Cluster Resilience
thatDot Streaming Graph is built from the ground up to run in a distributed fashion across a cluster of machines communicating over the network. Unreliable network communication can make this an extremely difficult challenge. This page describes the clustering model and how it provides resilience in a complex deployment environment.
Cluster Topology and Member Identity
The cluster topology is defined at startup. The Streaming Graph cluster has a fixed operational size specified by a config setting known as the target-size. An operating cluster will have this many members participating in the overall graph.
Each participant in a cluster is referred to as a member or cluster member. The machine a member is running on is referred to as a host.
Each member is assigned a unique integer defining its position in the cluster (from zero until the target size, exclusive). Once the cluster has filled all positions with live members, the cluster enters an Operating state.
If the cluster falls below the required number of cluster members to operate, it will enter a Degraded state where processing is paused until enough members have re-joined to become Operating again. Additional members that join the cluster are used as “hot-spares” to take over from any failed member of the cluster.
Hot Spares
Hot spares are members that are provisioned over and above the target size for the cluster. These machines are aware of the graph but do not participate actively. In the event of a cluster member failure, a hot spare will take over the corresponding position in the cluster, in place of the failed member. If the failed member is restarted, it will join the pool of hot spares. Because a member serving as a hot spare does not occupy a position in the cluster, its functionality is limited: While administrative routes like cluster status can be used, any APIs that interact with the graph or its data (standing queries, ingests, ad-hoc queries, etc) are unavailable on a hot spare. Accordingly, when interacting with a cluster, it is a good idea to use preflight API requests with a call to the cluster status endpoint in order to ensure that API requests are being sent to a positioned member rather than a hot spare member.
The recommended number of hot spares depends on the failure rate and scenarios of your cluster. At least one (1) hot spare is recommended to minimize downtime and maximize overall throughput for any installation. Additionally, we recommend one hot spare per physical rack in a cluster hosted in a datacenter. In a cloud environment where machines are managed, such as with Kubernetes, you may not need a hot spare at all depending on your downtime tolerance. The cluster is effectively paused until the replacement is in place.
If a hot spare is available, it is swapped in immediately, making it the best way to minimize downtime. Detecting and restarting failed members (or those ejected from the cluster) is an appropriate alternative solution in many deployments.
Member Identity
Cluster members are defined by both their position in the cluster and the host address/port they use to join the cluster. The position is a property of the cluster, while host address and port are properties of the joining member.
The position is an abstract identifier denoting a particular portion of the graph to serve. It has a value from 0 until quine.cluster.target-size of the cluster (originally set in the config at startup). The position is a logical identifier that is an attribute of the cluster and not directly tied capabilities or properties any member who might occupy that position. When operating, a member will fill exactly one position in the cluster. If that member leaves the cluster, the position will remain as empty or get filled by a new member.
Each member joins the cluster with a specific host address and port determined statically or dynamically when the member starts. These are properties of the joining members, and must be unique among all participants trying to join the cluster. A new member joining with the same address and port is treated as replacing the previous member with the same address/port. If this occurs, the original member is ejected from the cluster and the new member is added. A member’s address and port are specified in the config settings: quine.cluster.this-member.address and quine.cluster.this-member.port
The host address and port can be specified literally, or they can be determined dynamically at startup. The address value will be determined dynamically if either of the following values are provided:
<getHostAddress>will use the host IP found at runtime<getHostName>will use the host DNS name found at runtime
The port can be set to 0, which will assign it automatically at startup to a port available on that host.
Cluster Configuration
There are two methods to configure a cluster. The first involves specifying static seed addresses, which provide the address and port of cluster members. The second method utilizes DNS-based discovery to dynamically locate and connect to cluster nodes.
Cluster Seeds
Cluster seeds facilitate any new machine trying to join the cluster. A seed is defined as the host address and port of a specific member. To form a cluster, at least one seed in the joining member’s configuration much be reachable over the network, and that seed must be part of the cluster. It is recommended to include multiple seed nodes in each member’s configuration in case that member needs to join when one or more member (particular the seed node it specifies) is unreachable. This can be done by specifying a list in the config file, or at the command line in the following fashion, replacing the number in configuration key with the index of the item in the list being referred to:
cluster-join = {
type = static-seed-addresses
seed-addresses.0.address = 172.31.1.100
seed-addresses.0.port = 25520
seed-addresses.1.address = 172.31.1.101
seed-addresses.1.port = 25520
}
A member can specify its own host address and port as the seed node. If no other seeds nodes are provided or are unreachable, that member will form a cluster on its own and be available to add other members as the cluster seed.
DNS Discovery
In environments where cluster members are orchestrated by a scheduler such as Kubernetes, Streaming Graph can be configured to automatically form a cluster using DNS-based discovery. A DNS name (quine in this example) resolves to one or more Streaming Graph hosts as the cluster discovery mechanism.
cluster-join = {
type = dns-entry
name = quine
}
Clustered Persistence
Each position in a thatDot Streaming Graph cluster is responsible for managing a slice, or partition, of the nodes in the graph as a whole. Because hot spare members must occupy any position on short notice, the state of each position’s nodes is proactively persisted to a durable store. Additionally, certain metadata such as the definitions of Standing Queries running on the graph are used by all cluster members. This data can be considered owned by the graph as a whole, rather than by any individual position in the cluster. Between the shared metadata and the need for hot spare members to be able to take over any position, the cluster’s persistence backend must be shared by all cluster members.
Cassandra and ClickHouse are the two supported persistence backends for Streaming Graph when running in a cluster.
Depending on application requirements, you may need to supplement your cluster storage over time. For this reason, we recommend using Cassandra, which has a proven expansion model, for storage. We recommend using Cassandra’s TTL (time-to-live) setting to expire old data out of the application to bound total disk usage. ClickHouse does not have a native TTL solution for this, and would require a manual process to interact with the ClickHouse servers to facilitate this functionality. Alternatively, a service can make API//Cypher calls to purge data which is no longer needed, but this will require understanding the application and which data is safe to purge.
Cluster Formation
As members join the cluster, they are assigned a position. When all positions (determined by target-size) have been filled, the cluster will transition into an operating state. A cluster in an operating state is fully available and is ready to be used.
Cluster Life-cycle
A cluster has four phases to its life-cycle:
MemberStarting- a member is starting. It may or may not have found the cluster yet.Unavailable- the cluster needs to fill at least one position or drain activity from a subset of the cluster.Operating- the cluster is fully operational.ShutdownCommitted- shutdown preparation is complete and the cluster member will shut down.
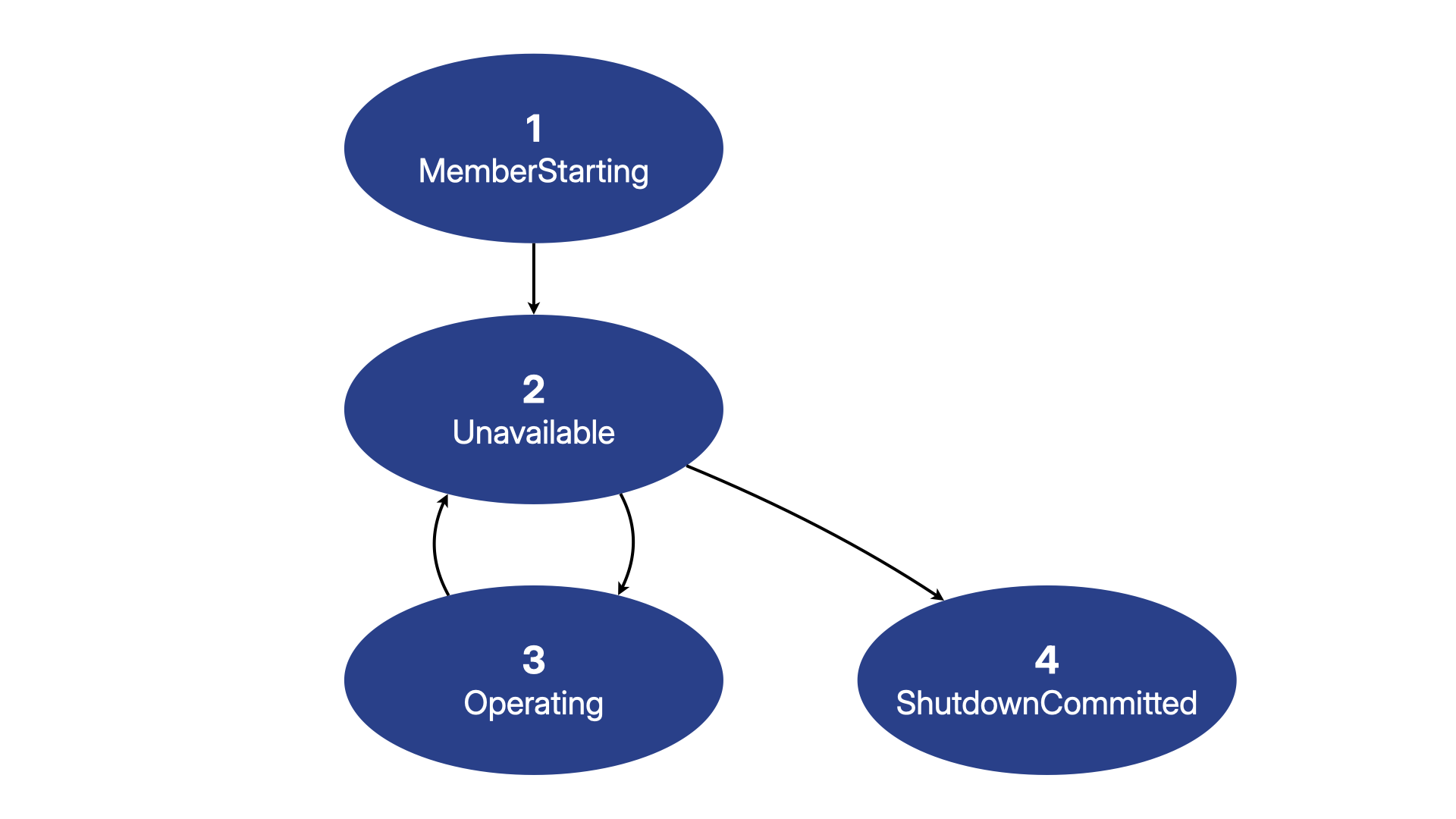
In general, these phases progress linearly. Exceptions to this linear progression include the possibility that a cluster can transition:
- from
OperatingtoUnavailableif a positioned member is lost or activity needs to be drained - from
Unavailableback toUnavailablewhen the number of positioned members changes (up or down) but is still below thetarget-size - from
Unavailableback toUnavailablewhen it is attempting to fill positions and return toOperatingbut receives a request to shut down the whole cluster - from
UnavailabletoShutdownCommittedwhen a cluster shutdown has been requested and all activity has been drained
There is a single progression through these states for the entire cluster, although a member may see just a valid subset of that history. There is a synchronization point when the cluster transitions from Unavailable to Operating where all members must acknowledge the configuration of the cluster that has become eligible to return to Operating.
Handling Failure
Failure handling is entirely automatic in thatDot Streaming Graph. Internal processes use distributed leader election, gossip protocols, failure detection, and other distributed systems techniques to detect server failure and decide on the best course of action.
Failure Detection
Detecting failed machines in the context of distributed systems is a fundamental challenge. It is impossible to determine on one system whether another system has failed, or whether it is just slow to respond — maybe because it is working hard. This fundamental logical constraint requires every distributed system to use time to make a judgement call about the health of other systems.
Member Failure Detector
thatDot Streaming Graph uses Phi-Accrual Failure Detection to monitor the health of all cluster members. When a cluster member is unresponsive, it results in an exponentially growing confidence that the unresponsive member should be interpreted as failed. When the confidence is high enough, the decision is made by the clusters elected leader to treat the unresponsive member as unreachable. An unreachable member is given a grace period (primarily based on the cluster composition) before it is ejected from the cluster.
When an active member is ejected, the cluster enters a degraded state. From that point on, if the machine resumes activity, it will not be allowed to participate in the cluster. When a thatDot Streaming Graph cluster member experiences this, it will shut itself down. If the application is started again on the same host and port, it will be able to re-join the cluster. It may find that its previous position is still open and then fill slot again after restarting, or if a hot-spare was available, it will find that its position was quickly filled, and the restarted machine will become a hot-spare.
Cluster Partition Detection
Networks are inherently unreliable. A cluster communicating across a network faces the logical danger that a partition in the network can result in a division of the cluster where each side believes it is the surviving half. To overcome this challenge, thatDot Streaming Graph uses Pekko’s Split Brain Resolver to detect this situation and determine which cluster partition should survive.
Automatic Failure Recovery
With thatDot Streaming Graph able to detect failed members, restore them quickly from hot-spares, and protect against cluster partitions, the operational demands on the people who manage it are greatly reduced. A thatDot Streaming Graph cluster will remain operating as long as there are enough active members to meet or exceed the target-size. Any number of hot-spares can be added to the cluster to achieve any level of resilience the operator desires.
Inspecting the Live Cluster
The current status and recent history of the cluster is available for human or programmatic inspection from the administration status endpoint: GET /api/v1/admin/status. See the built-in documentation or reference section of the documentation for more details.