Operational Considerations
Deploying: Basic Resource Planning
Quine is extremely flexible in its deployment model. It is robust and powerful enough to run on a server with hundreds of CPU cores and terabytes of RAM, but also small and lightweight enough to run on a Raspberry Pi.
Quine is a backpressured system; it will deliberately slow down when resource-constrained. This is a highly desirable quality because the only alternative is to crash the system. Making Quine run faster is essentially a matter of allocating resources to the machine/environment so that the slowest component is not a bottleneck.
CPU
As a distributed system, Quine is designed from the ground up to take advantage of multiple CPU cores. Quine will automatically configure increased parallelism where there are more CPU cores available. This configuration can be customized using the Akka configuration settings for the default-dispatcher when starting up Quine.
High CPU Utilization
By design, we expect Quine to utilize as many resources as it is allotted. High CPU usage alone, without additional symptoms, is desirable and reflects good utilization of the system.
Low CPU Utilization
Quine is designed to use backpressure to limit incoming data from producers. If any aspect of the graph is overwhelmed in the cluster (e.g. the data storage layer is slow), Streaming Graph will backpressure incoming data to ensure all work can complete. This mechanism provides data safety by not dropping incoming records, and system resilience by not sending more data than the graph can handle. To understand if the ingest is backpressuring, view the shared.valve.ingest.{ingest-name}.metric to see if the value is increasing. A higher value means more backpressure.
If the ingest stream parallelism setting is too low, the system may not take advantage of all the parallel processing it is capable of. This setting determines how many items from the ingest source will be causing their effects in parallel. Too low of a parallelism setting will cause the CPU to be underutilized.
Variable CPU Utilization Between Members
If some Quine cluster members have high CPU utilization and others have low CPU utilization, it may or may not be a concern. The variation indicates an imbalance in the workload among members. Depending on the use case, that might be expected.
Even if it is not expected, it can be a temporary occurrence; for instance when a cluster member is replaced by a hot spare and the newly active member is warming up its data cache, causing some queries to be backpressured on other members.
If the condition persists and is unexpected, it can be caused by data modeling choices; for instance when a node in the graph is particularly hot, or has become a supernode. See the section on supernode mitigation.
RAM
System memory (RAM) is used by Quine primarily to keep nodes in the graph warm in the cache. When a node required for a query or operation is needed, if it is live in the cache, then calls to disk can often be entirely avoided. This significantly increases performance and throughput of the system overall. So in general, the more nodes live in the cache, the faster the system will run.
Quine uses a novel caching strategy that we call “semantic caching”. The net result is that there is a decreasing benefit to having additional nodes kept in memory. There is only a performance improvement if those nodes are needed.
Since Quine runs in the JVM, you can have Quine use additional system RAM in the standard Java fashion by increasing the maximum heap size with the -Xmx flag when starting the application. E.g.: java -Xmx6g -jar {{ quine }} In order for Quine to receive a benefit from increased RAM, you will probably also need to increase the limit of nodes kept in memory per shard by changing the in-memory-soft-node-limit, and possibly the in-memory-hard-node-limit sizes. See the Configuration Reference for details. The ideal setting for these limits depends on the use case and will vary. We suggest monitoring usage with the tools described below to determine the best settings for your application. In-memory node limits can be changed dynamically from the built-in REST API with the shard-sizes endpoint.
Keep in mind that setting the maximum heap size is not the same as limiting the total memory used by the application. Some amount of additional off-heap memory will be used when the system is operating normally. Off-heap memory usage is usually trivial, but can become significant in some cases, e.g.: Lots of network traffic, or using memory mapped files. The latter case can becomes very significant when using the MapDB persistor, which defaults to using memory mapped files for local data storage.
Out of Memory Error
Quine can be configured to use any amount of RAM. The settings for in-memory-soft-node-limit and in-memory-hard-node-limit should be adjusted according to the workload in proportion to the amount of memory available on the system. If you encounter an Out-of-Memory error, we suggest lowering the soft limit. This setting can be adjusted while the system is running via an API call.
Storage
Quine stores data using one or more Persistor. Persistors are either local or remote. A local persistor will store data on the same machine where Quine is running, at a location in the filesystem determined by its configuration. A remote persistor will store data on a separate machine. By default, Quine will use the local RocksDB persistor.
For production deployments, we recommend using a remote persistor like Cassandra to provide data redundancy and high-availability. Additionally, old data can be expired from disk using Cassandra’s time-to-live setting in order to limit the total size of data stored.
Network
Imbalanced Network, RAM, or CPU, Activity
When viewing resource usage for a cluster, it’s common to see different usage profiles on different hosts. This is entirely normal. Due to the underlying nature of the distributed graph, there may be queries that need to read from, and/or write to, specific members in the cluster.
Historical Query Latency
In a clustered environment, some queries may need to traverse multiple members in order to satisfy a given request. When multiple machines are involved, there is always a chance of clock skew across servers. When this happens, in the worst case, thatDot Streaming Graph will delay the response by the amount equal to the time deviation between systems to ensure correctness.
Member Outage
In the event that a cluster member actively participating in the graph becomes unavailable, some or all graph processing will pause. If the cluster member resumes operation, the graph processing will resume. However, if the cluster removes the unresponsive member, a hot spare will be promoted into service to take the place of the compromised cluster member. If the unavailable member resumes operation at this point, it will shut itself down and can be safely restarted to participate in the cluster again (as hot spare or otherwise as needed). If there are more outages than hot spares, then the cluster will be effectively “down” until replacements have been provisioned for all cluster members.
Application/JVM
Process Killed
If the operating system kills the process, it is likely due to insufficient RAM available for the total workload managed by the OS. Like most JVM applications, thatDot Streaming Graph uses RAM for the heap, but also for off-heap allocations. We recommend setting a lower Java heap size to allow some RAM to be used by off-heap allocations. We also suggest that you do not run other processes on the same machines running Streaming Graph.
Application Won’t Start
If the application will not start, ensure that the resources you are allocating to the system are actually available. thatDot Streaming Graph operates in a JVM and can be tuned accordingly. If there are other services hosted on the same machine with Streaming Graph, ensure that all services can operate with the available system resources. We recommend running Streaming Graph without other intensive services on the same machine for most deployments.
Pekko Heartbeat Warning/Timeout
In clustered operation, sometimes log messages such as:
[quine-cluster-pekko.actor.default-dispatcher-19] org.apache.pekko.remote.PhiAccrualFailureDetector - heartbeat interval is growing too large for address pekko://quine-cluster@10.0.15.51:25520: 2585 millis
This can be caused by network latency, but often this can be due to CPU limits created by virtualization layers such as Docker or Kubernetes. If CPU limits are the cause, the recommended solution is to remove CPU limits which utilize CFS (Completely Fair Scheduler).
In Docker, this can be done by avoiding the use of the --cpus and --cpu-quotas options, opting instead for the --cpu-shares option instead if necessary.
In Kubernetes, this can be done by avoiding the use of resource limits for Streaming Graph pods or, if necessary, ensuring those limits are set to at least double the resource requests for each pod.
See this Akka documentation page for more information on deploying to Docker or Kubernetes.
Monitoring
It is often helpful to watch an operating system to confirm it is behaving as anticipated. Quine includes multiple mechanisms for monitoring a running system.
Web Browser
A basic operational dashboard is built into the pages served from the Quine web browser.
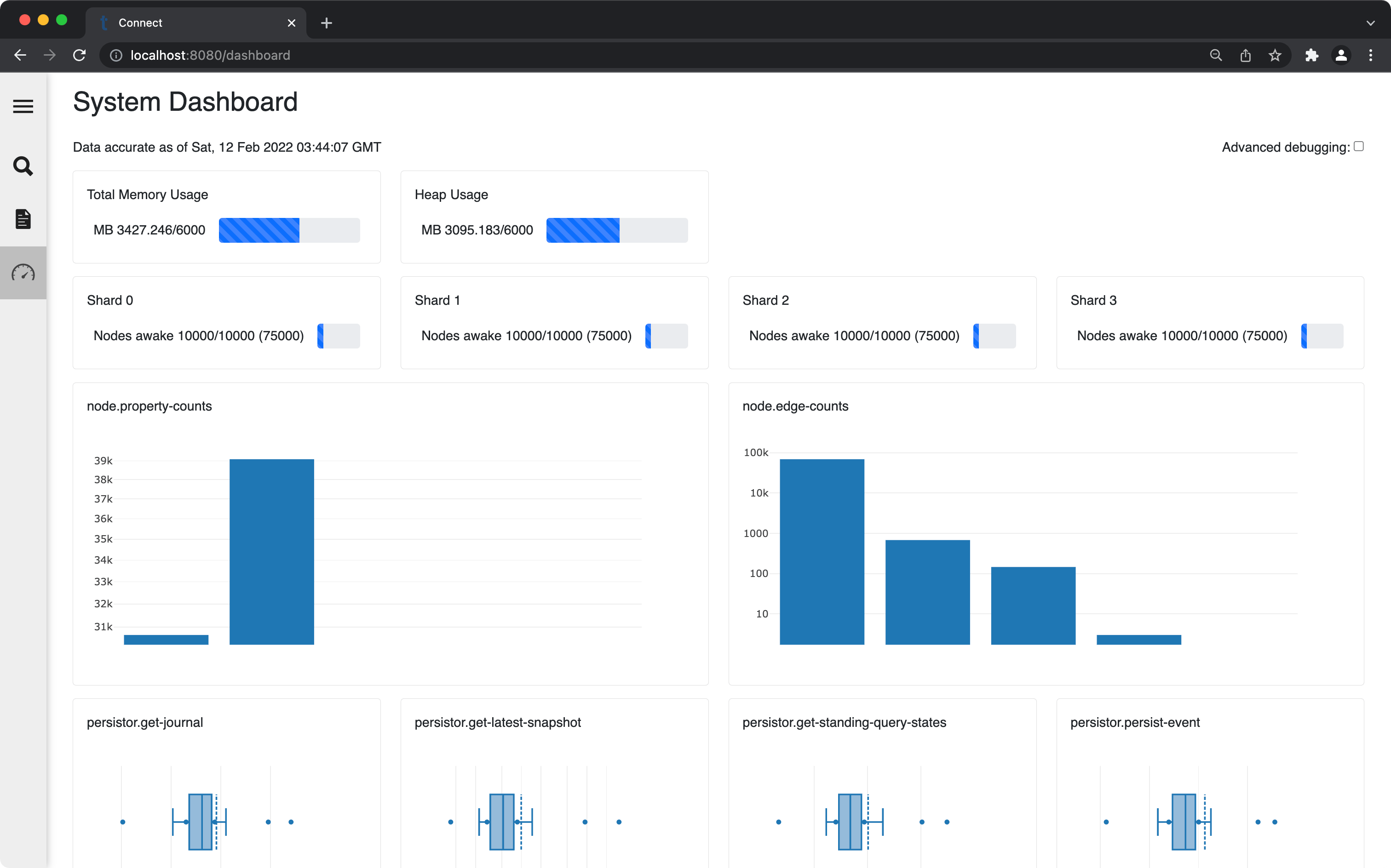
This page includes live updating reports on memory usage, nodes in the cache (per shard), basic histograms of the the number of properties and edges per node, and latency measurements of various important operations.
REST API
Quine serves a REST API from its built-in web server. That web server provides separate readiness and liveness API endpoints for monitoring the status of the Quine system. Detailed metrics can be retrieved from the endpoint: GET /api/v1/admin/metrics
JMX
Quine can be monitored and controlled live using JMX. There is a wide array of tools available for monitoring JVM applications through JMX. If you don’t already have a preference, you might start with VisualVM.