Writing Standing Queries
Output action
Once you’ve decided what graph structure to watch for, the second half of a Standing Query is deciding what to do with the results. This step can be initially skipped as Standing Query outputs can always be added even after the query is running, with the /api/v1/query/standing/{name}/output endpoint. The information that is produced for each result includes:
-
Query data returned from the “match” portion (e.g. the ID of the node). This is structured as an object whose keys are the names of the values returned (ex:
RETURN DISTINCT strId(n)would have key"strId(n)"andRETURN DISTINCT id(n) AS theIdwould have key"theId"). The intuition is that each query data returned is analogous to a row returned from a regular Cypher query - the key names match what would normally be Cypher column names. -
Meta information
-
isPositiveMatch: whether the result is a new match. When this value is false, it signifies that a previously matched result no longer matches -
resultId: a UUID generated for each result. This is useful if you wish to track a result in some external system, since theresultIdof the result withisPositiveMatch = falsewill match theresultIdof the original result (whenisPositiveMatch = true).
-
A result is emitted when the pattern matches or when it stops matching, but extra results won’t be emitted if there are new ways the pattern can match.
Consider the following query for watching friends.
// Find people with friends
MATCH (n:Person)-[:friend]->(m:Person)
RETURN DISTINCT strId(n)
If we start by creating disconnected “Peter”, “John”, and “James” nodes, there will be no matches.
CREATE (:Person { name: "Peter" }),
(:Person { name: "John" }),
(:Person { name: "James" })
Then, if we add a “friend” edge from “Peter” to “John”, “Peter” will trigger a new Standing Query match.
MATCH (peter:Person { name: "Peter" }), (john:Person { name: "John" })
CREATE (peter)-[:friend]->(john)
However, adding a second “friend” edge from “Peter” to “James”, “Peter” will not trigger a new match since he is already matching (that is, the “Peter” node is not distinct).
MATCH (peter:Person { name: "Peter" }), (james:Person { name: "James" })
CREATE (peter)-[:friend]->(james)
There are pre-built output adapters for at least the following (this list is continually growing — refer to the Standing Query section of the REST API for an exhaustive list):
- publishing to a Kafka topic
- publishing to an AWS Kinesis stream
- publishing to AWS SQS and SNS
- logging to a file
POST-ing results to an HTTP endpoint- executing another Cypher query
The last of these options is particularly powerful, since it makes it possible to mutate the graph in a way that can trigger another Standing Query result into any other output adapter. This makes it possible to post-process results to collect more information from the graph or to filter out matches that don’t meet some requirement.
Cypher Query as an Output
The Cypher query output is defined in terms of a regular Cypher query that is run for each result produced by the Standing Query. The results from the Standing Query are available under a Cypher query parameter — see the 3D data tutorial for an end-to-end example of this. To make sure the query is correct and the desired results are matched, it is highly recommended that the output query be tested independently in the Exploration UI.
Inspecting Running Queries
Since Standing Queries use a subset of regular Cypher query syntax, the Standing Query itself can be run as a regular query either to see what data already in the graph would have been matched by the query or to understand why a particular node in the graph is not a match. When doing so, you should constrain the starting points of the query if there is already a large amount of data in the system (see querying infinite data).
In addition, there are a couple ways to “wiretap” results as they are being produced and inspect them live. These are meant primarily as debug mechanisms - not substitutes for outputs.
standing.wiretap Cypher procedure
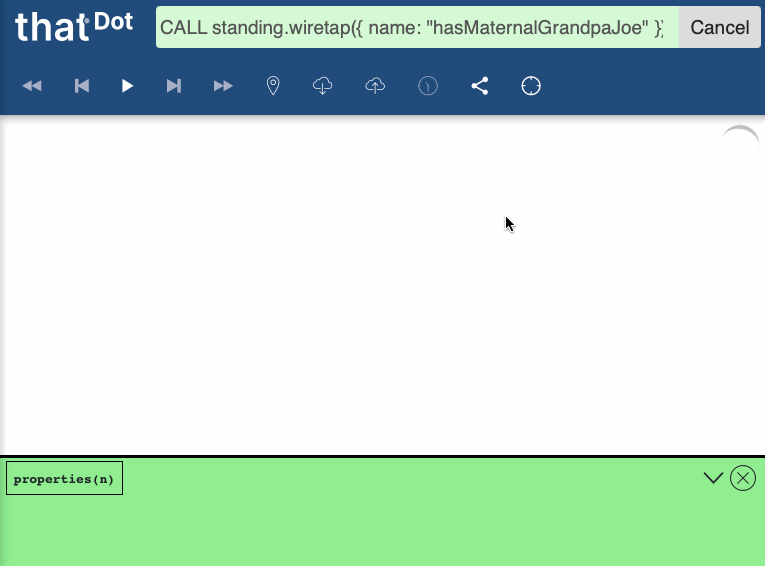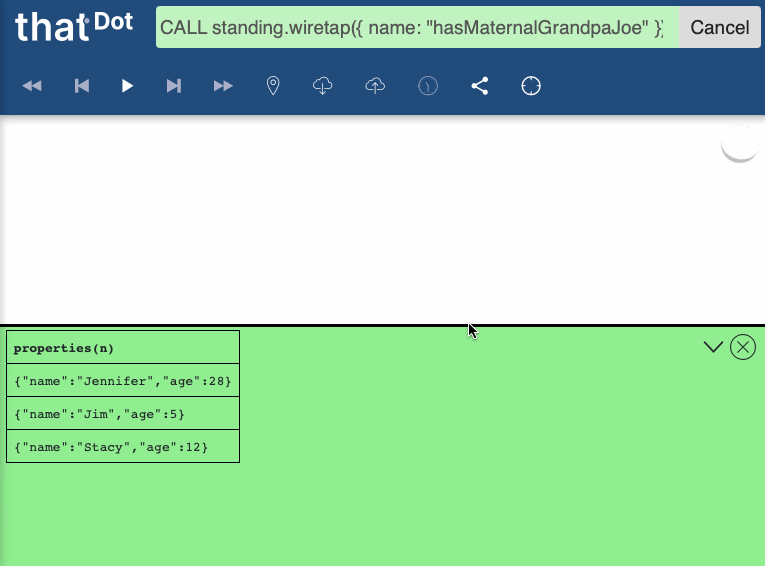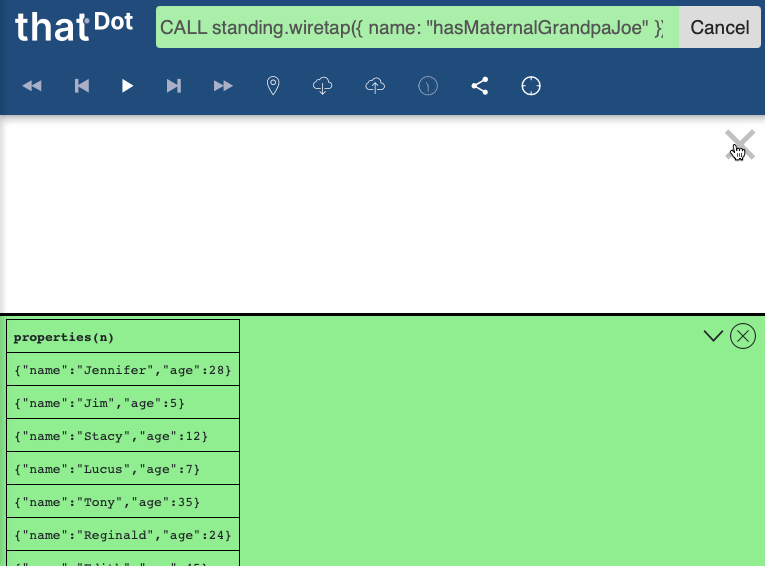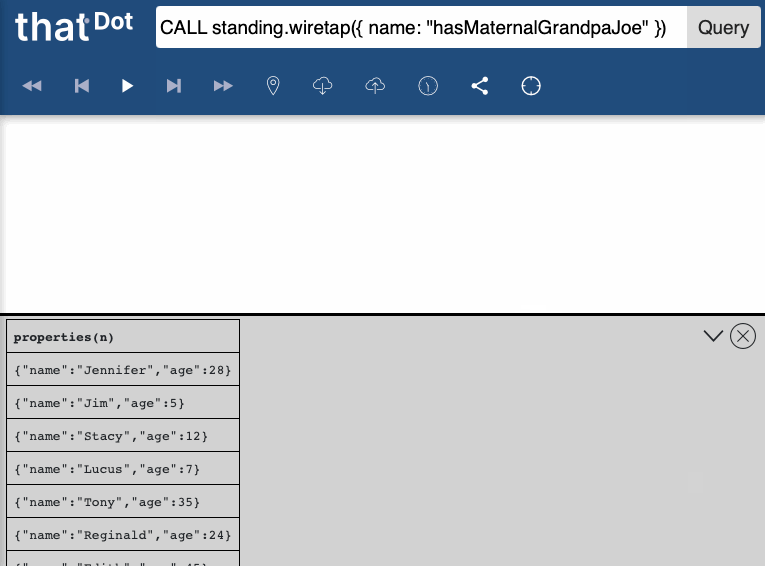
From the Exploration UI, the standing.wiretap Cypher procedure can be used to issue a query that will incrementally return results. Since this is just a regular, Cypher procedure, it can feed its outputs automatically into another query too. For example:
// Wiretap "hasMaternalGrandpaJoe" and return properties of matching nodes
CALL standing.wiretap({ name: "hasMaternalGrandpaJoe" }) YIELD meta, data
WHERE meta.isPositiveMatch
MATCH (n) WHERE id(n) = data.id
RETURN properties(n)
Then, you will see results incrementally appear as they match. When you are satisfied, you can cancel the query.
The standing.wiretap procedure only stops running if the standing query is cancelled (since otherwise it can never be certain that there won’t be more forthcoming match results). This means that it is risky to use the procedure in the Cypher REST API or in other places where results are not reported incrementally and queries cannot be cancelled.
SSE endpoint
It is also possible to wiretap results outside of the Exploration UI (and without going through the standing.wiretap Cypher procedure) by using the SSE endpoint /api/v1/query/standing/{standingQueryName}/results. That endpoint will surface new matches as they are being produced. The Chrome web browser, for example, will continue to append new results to the bottom of the page as they become available. curl will print out new results as they arrive.
$ curl http://localhost:8080/api/v1/query/standing/hasMaternalGrandpaJoe/results
data:
data:
data:{"data":{"id":"2756309260014435"},"meta":{"isPositiveMatch":true}}
event:result
id:8f408026-8fb3-3955-c81a-7259175f41b8
data:{"data":{"id":"7945274922095468"},"meta":{"isPositiveMatch":true}}
event:result
id:6a83dda3-08a1-e085-ee7d-14138398f336
data:{"data":{"id":"6994090876991233"},"meta":{"isPositiveMatch":true}}
event:result
id:59b215b4-4084-b5bb-379d-9654bb2a7c83
data:
Using the output above, it is possible to query the matching nodes directly with a Cypher query. For instance, we can go look for current children of some of the matches the SSE output above tells us we found:
// Query for children of nodes with IDs from the SSE endpoint above
UNWIND [2756309260014435, 7945274922095468, 6994090876991233] AS personId
MATCH (person)<-[:has_mother|:has_father]-(child) WHERE id(person) = personId
RETURN person.name, child.name, child.yearBorn
Querying for a matched node is especially useful if there is a Cypher query registered as one of the outputs of the Standing Query and if that second query modifies the data — for instance, adding an edge connected to the node.