Quick Start
What is Streaming Graph
Streaming Graph combines the real-time event stream processing capabilities of systems like Flink and ksqlDB with a graph-structured data model as found in graph databases like Neo4j and TigerGraph. Streaming Graph is a key participant in a streaming event data pipeline that consumes data, builds it into a graph structure, runs computation on that graph to answer questions or compute results, and then stream them out.
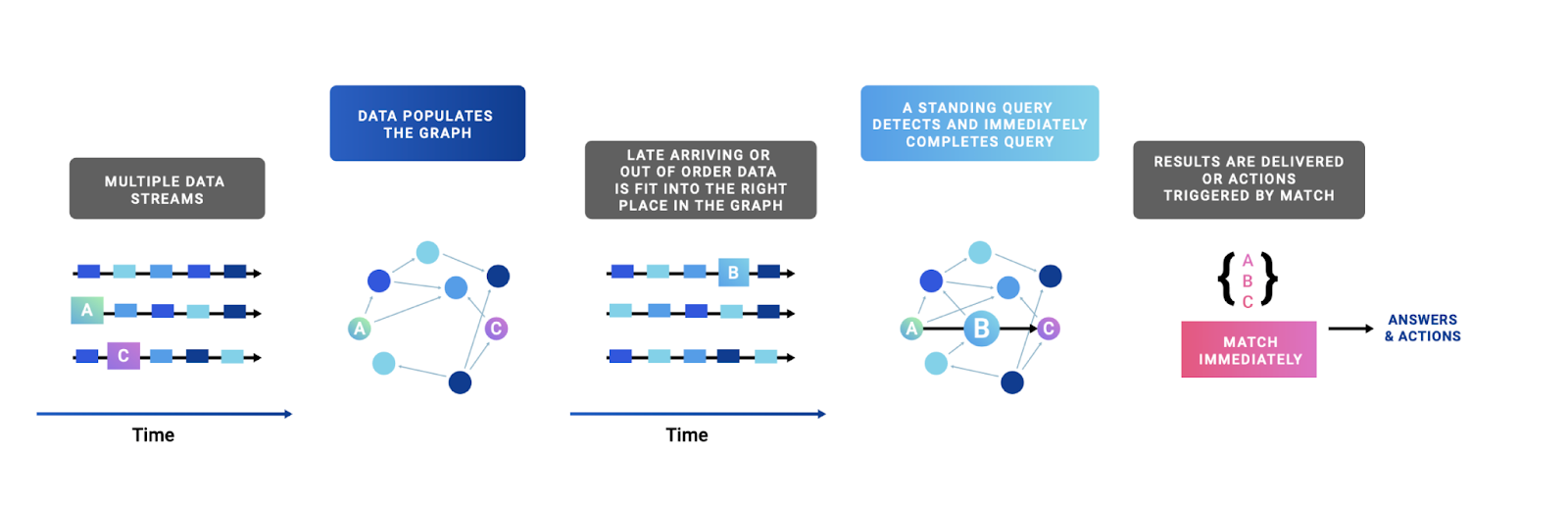
All together, Streaming Graph can:
- Ingest high-volume streaming event data from stream processing systems like Kafka, Kinesis, APIs or databases/data warehouses
- Convert and merge it into durable, versioned, connected data (a graph)
- Monitor that connected data for complex structures or values
- Trigger arbitrary computation in the event of each match
- Emit high-value events out to stream processing systems like Kafka, Kinesis, APIs or databases/data warehouses
This collection of capabilities represents a complete system for stateful event-driven arbitrary computation in a platform scalable to any size of data or desired throughput.
Before you begin
Concepts that you should already be familiar with:
- Event driven architectures
- Graph database concepts
- Cypher graph query language
- Interacting with REST API endpoints
Running the trial version of Streaming Graph requires an API Key. To get an API Key, you can follow these instructions for detailed steps on where to fill out a form to receive a key, how to configure Streaming Graph, and how to run an instance. The summary of it is this:
- Fill out Free Trial Form and Receive API Key
- Download Streaming Graph Free Trial
- Configure and run Streaming Graph
Starting the thatDot Streaming Graph instance should output some trial license information and should show that the Streaming Graph web server is ready to serve requests at localhost:8080

It may also help to read Streaming Graph’s Main Concepts before starting.
Connect to Streaming Graph
There are two main structures that you need to configure in Streaming Graph; the ingest stream forms the event stream into the graph, and standing queries which match and take action on nodes in the graph. Follow the links in the tutorial to the API documentation to learn more about the schema for each object.
Connect an Event Stream
For example, let’s ingest the live stream of new pages created on Wikipedia; mediawiki.page-create .
Create a “server sent events” ingest stream to connect Streaming Graph to the page-create event stream using the ingest API endpoint.
Issue the following curl command in a terminal running on the machine were you started Streaming Graph.
curl -X "POST" "http://127.0.0.1:8080/api/v1/ingest/wikipedia-page-create" \
-H 'Content-Type: application/json' \
-d $'{
"format": {
"query": "CREATE ($that)",
"parameter": "that",
"type": "CypherJson"
},
"type": "ServerSentEventsIngest",
"url": "https://stream.wikimedia.org/v2/stream/page-create"
}'
Congratulations! You are ingesting raw events into Streaming Graph and manifesting nodes in the graph.
Let’s look at a node to see what it contains by submitting a Cypher request via the query/cypher API endpoint.
curl -X "POST" "http://127.0.0.1:8080/api/v1/query/cypher" \
-H 'Content-Type: text/plain' \
-d "CALL recentNodes(1)"
This query calls the recentNodes Cypher procedure to retrieve the most recent one (1) node.
{
"columns": [
"node"
],
"results": [
[
{
"id": "7a9a936f-ae1a-49c5-ba99-0ec6401bfd7d",
"labels": [],
"properties": {
"database": "enwikisource",
"rev_slots": {
"main": {
"rev_slot_content_model": "proofread-page",
"rev_slot_origin_rev_id": 12558576,
"rev_slot_sha1": "lqrhvc49cgzegvvfqnzg3c6bpxs55up",
"rev_slot_size": 1699
}
},
"rev_id": 12558576,
"rev_timestamp": "2022-08-23T18:34:25Z",
"rev_len": 1699,
"rev_minor_edit": false,
"parsedcomment": "<span dir=\"auto\"><span class=\"autocomment\">Proofread</span></span>",
"page_title": "Page:The_Works_of_H_G_Wells_Volume_6.pdf/423",
"rev_content_format": "text/x-wiki",
"page_id": 4034745,
"page_is_redirect": false,
"meta": {
"domain": "en.wikisource.org",
"dt": "2022-08-23T18:34:25Z",
"id": "3c8c9150-19aa-4f33-be5d-bf3ef8d8a994",
"offset": 241649600,
"partition": 0,
"request_id": "0ba80d5c-3c97-4971-b0d2-360c5d20e0f6",
"stream": "mediawiki.page-create",
"topic": "eqiad.mediawiki.page-create",
"uri": "https://en.wikisource.org/wiki/Page:The_Works_of_H_G_Wells_Volume_6.pdf/423"
},
"page_namespace": 104,
"rev_sha1": "lqrhvc49cgzegvvfqnzg3c6bpxs55up",
"comment": "/* Proofread */",
"rev_content_model": "proofread-page",
"$schema": "/mediawiki/revision/create/1.1.0",
"performer": {
"user_edit_count": 10176,
"user_groups": [
"autopatrolled",
"*",
"user",
"autoconfirmed"
],
"user_id": 141433,
"user_is_bot": false,
"user_registration_dt": "2009-07-12T12:33:52Z",
"user_text": "MER-C"
}
}
}
]
]
}
The API call is the functional equivalent to issuing the CALL recentNodes(1) query in the Exploration UI: 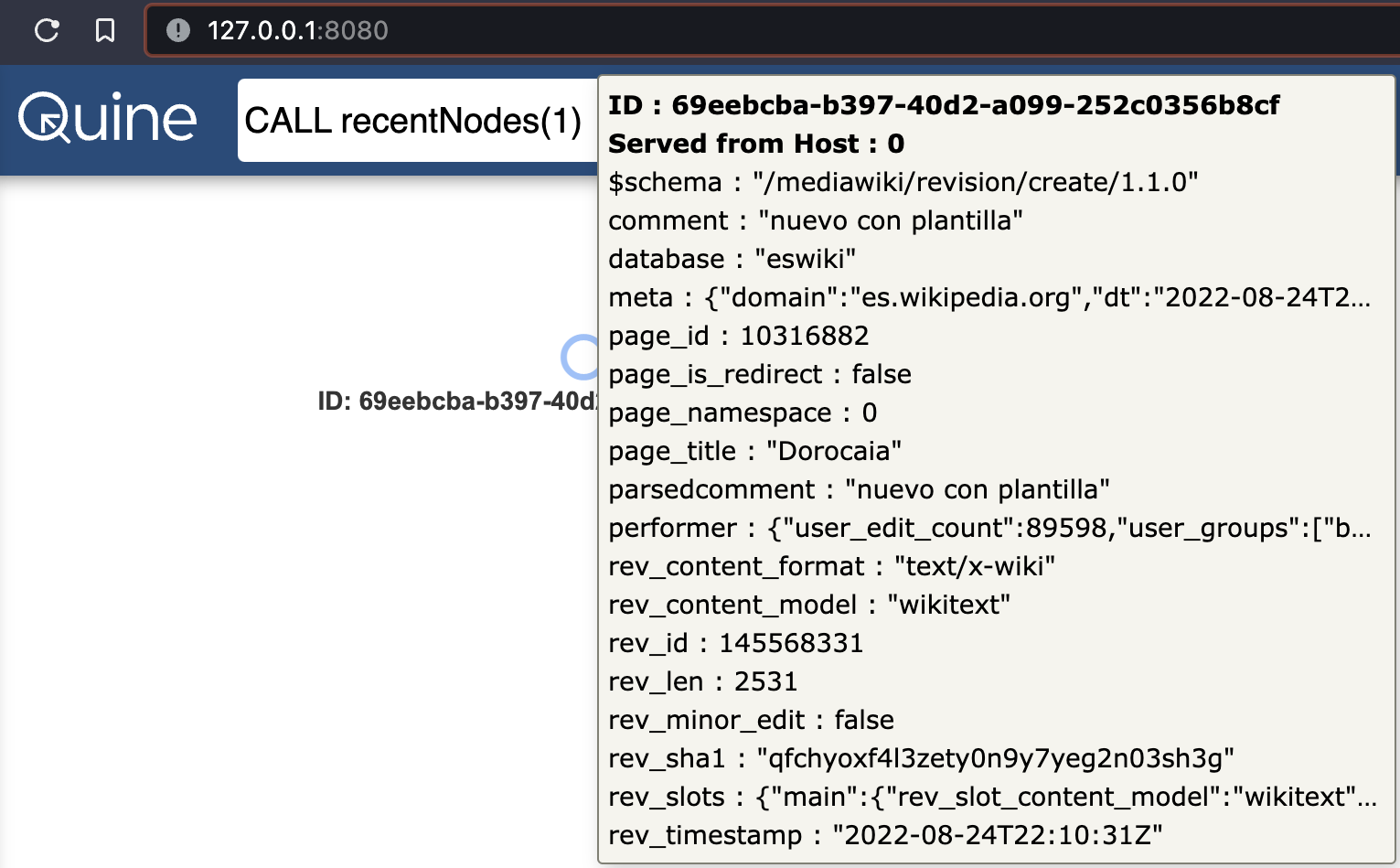
!!! Note Your API response will contain a different set of parameters than above because you are ingesting a stream of live events from Wikipedia.
This ingest stream is performing the most basic of ETL functionality, it manifests a disconnected node directly from each event emitted from the Wikipedia event stream.
Create a Standing Query
A Standing Query matches some graph structure incrementally while new event data is ingested. Creating a standing query is done with a single call to the standing/query API endpoint.
Right now, Streaming Graph is the only component in our data pipeline. Let’s configure a standing query that watches for new nodes to enter the graph and print the node contents to the console.
!!! Note A standing query can emit the event data, re-form the event into new events, or trigger actions to inform elements downstream in your data pipeline (e.g., a Kafka topic).
curl -X "POST" "http://127.0.0.1:8080/api/v1/query/standing/wikipedia-new-page-node" \
-H 'Content-Type: application/json' \
-d $'{
"pattern": {
"query": "MATCH (n) RETURN DISTINCT id(n)",
"type": "Cypher"
},
"outputs": {
"print-output": {
"type": "PrintToStandardOut"
}
}
}'
You will see new node events similar to the one below appear in the same console window where you launched Streaming Graph immediately after running the curl command. These events contain the id of each new node created in the graph.
2022-08-23 14:06:55,174 Standing query `print-output` match: {"meta":{"isPositiveMatch":true,"resultId":"dab367a3-b272-7dba-c12e-a65bc9f5e0b8"},"data":{"id(n)":"911d88e0-413a-42bd-a0f8-dd15bbf6aff6"}}
Ending the Stream
This quick-start is a foundation that you can build on top of to ingest and interpret your own streams of data. But for now, we can pause the ingest stream and shutdown Streaming Graph before moving on.
curl -X "PUT" "http://127.0.0.1:8080/api/v1/ingest/wikipedia-page-create/pause"
curl will return a confirmation that the ingest stream is paused and metrics about what had been ingested to that point.
{
"name": "wikipedia-page-create",
"status": "Paused",
"settings": {
"format": {
"query": "CREATE ($that)",
"parameter": "that",
"type": "CypherJson"
},
"url": "https://stream.wikimedia.org/v2/stream/page-create",
"parallelism": 16,
"type": "ServerSentEventsIngest"
},
"stats": {
"ingestedCount": 3096,
"rates": {
"count": 3096,
"oneMinute": 1.1004373606561983,
"fiveMinute": 1.1045410320126854,
"fifteenMinute": 1.123947504968256,
"overall": 1.12992666124191
},
"byteRates": {
"count": 4471549,
"oneMinute": 1529.8568026569903,
"fiveMinute": 1553.9585381108302,
"fifteenMinute": 1614.01351325884,
"overall": 1631.9520432126692
},
"startTime": "2022-08-23T18:30:58.571823Z",
"totalRuntime": 2739271
}
}
You can stop Streaming Graph by either typing CTRL-c into the terminal window or perform a graceful shut down by issuing a POST to the admin/shutdown endpoint.
curl -X "POST" "http://127.0.0.1:8080/api/v1/admin/shutdown"
Next Steps
Learn how Streaming Graph uses Quine Recipes to store a graph configuration and UI enhancements in the Quine Recipes getting started guide.